Is This AGI? Google’s Gemini 3 Deep Think Shatters Humanity’s Last Exam And Hits 84.6% On ARC-AGI-2 Performance Today

Publish Date: 2026-02-12 17:13:00
Source Domain: www.marktechpost.com
Google announced a major update to Gemini 3 Deep Think today. This update is specifically built to accelerate modern science, research, and engineering. This seems to be more than just another model release. It represents a pivot toward a ‘reasoning mode’ that uses internal verification to solve problems that previously required human expert intervention.
The updated model is hitting benchmarks that redefine the frontier of intelligence. By focusing on test-time compute—the ability of a model to ‘think’ longer before generating a response—Google is moving beyond simple pattern matching.
 https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/
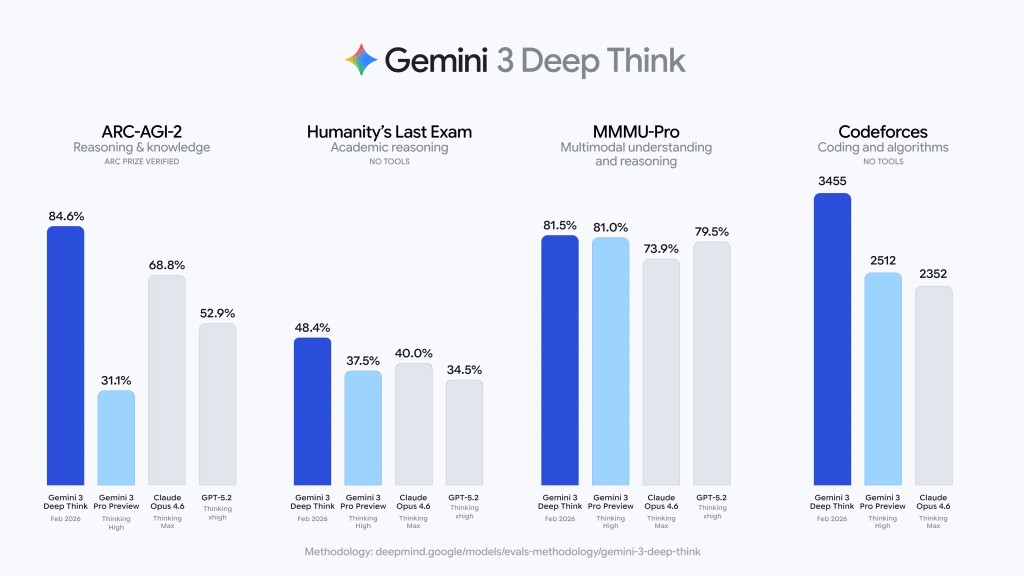
Redefining AGI with 84.6% on ARC-AGI-2
The ARC-AGI benchmark is an ultimate test of intelligence. Unlike traditional benchmarks that test memorization, ARC-AGI measures a model’s ability to learn new skills and generalize to novel tasks it has never seen. Google team reported that Gemini 3 Deep Think achieved 84.6% on ARC-AGI-2, a result verified by the ARC Prize Foundation.
A score of 84.6% is a massive leap for the industry. To put this in perspective, humans average about 60% on these visual reasoning puzzles, while previous AI models often struggled to break 20%. This means the model is no longer just predicting the most likely next word. It is developing a flexible internal representation of logic. This capability is critical for R&D environments where engineers deal with messy, incomplete, or novel data that does not exist in a training set.
Passing ‘Humanity’s Last Exam‘
Google also set a new standard on Humanity’s Last Exam (HLE), scoring 48.4% (without tools). HLE is a benchmark consisting of 1000s of questions designed by subject matter experts to be easy for humans but nearly impossible for current AI. These questions span specialized academic topics where data is scarce and logic is dense.
Achieving 48.4% without…


